
User-space filesystems allows developers to implement custom storage backends without modifying the kernel. At the heart of this capability is FUSE—Filesystem in Userspace. When combined with a safe system programming language like Rust, we can develop more robust, concurrent and safe FUSE filesystems.
In this article, we will walk through our experience using Rust to build an asynchronous FUSE-based filesystem: libfuse-fs. It is now used in Scorpio, an adaptive Git client for monorepos that provides filesystem support. Scorpio is part of the mega, a monorepo & monolithic codebase management system with Git support. It is also integrated into rk8s, a Lite Version of Kubernetes, for image building, serving as the filesystem layer.
Specifically, we'll cover:
- What FUSE is and why it's useful
- An overview of major Rust FUSE libraries
- The library we developed for our project
- Challenges we encountered and how we solved them
1. What Is FUSE
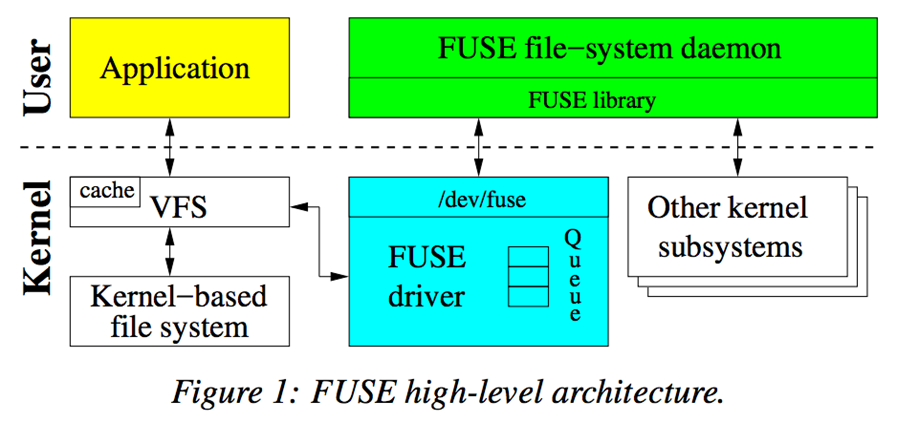
FUSE (Filesystem in Userspace) is a Linux kernel feature that allows userspace programs to implement fully functional filesystems without touching kernel space. It works by forwarding filesystem-related system calls (like read, write, getattr, etc.) to a userspace daemon via a special device node, typically /dev/fuse.
How FUSE works
- The kernel receives a VFS operation (e.g., triggered by commands such as
lsorcat).- If the target is a FUSE-mounted file system, the VFS hands the operation to the FUSE driver in the kernel. The driver encapsulates the operation into a FUSE request and places it into the request queue associated with
/dev/fuse.- The userspace FUSE daemon, linked with the FUSE library, reads requests from this queue, performs the necessary file system logic, and writes the results back to
/dev/fuse.- The FUSE driver dequeues the response and delivers it to the VFS, which in turn returns the result to the originating process.
2. FUSE Libraries in Rust
Table below lists several commonly used FUSE libraries implemented in Rust.
| Library Name | Type | Repository URL | Star | Update |
|---|---|---|---|---|
| fuse-rs | Synchronous FUSE Library | https://github.com/zargony/fuse-rs | 1.1k | 2021(inactive) |
| fuser | Synchronous FUSE Library | https://github.com/cberner/fuser | 1K | active |
| fuse3 | Asynchronous FUSE Library | https://github.com/sherlock-holo/fuse3 | 112 | active |
| fuse-mt | Multi-threaded Wrapper Library | https://github.com/wfraser/fuse-mt | 117 | 2023(inactive) |
| fuse-backend-rs | FUSE Daemon Library | https://github.com/cloud-hypervisor/fuse-backend-rs | 151 | 4 months ago(2025.4) |
- Fuse-rs – Synchronous FUSE Library
Pure Rust, strongly typed, memory safe. Simple API via fuse::Filesystem. Best for beginners and small filesystem prototypes. 5YEARS OLD
- fuser– Modern Synchronous FUSE Library
Active replacement for fuse-rs with cleaner, Rust-idiomatic API. Supports single & multi-threaded modes. Suitable for production. 5YEARS OLD
- fuse3 – Asynchronous FUSE Library
Async model, multi-core optimized, supports unprivileged mounts, readdirplus, POSIX locks. Ideal for high-performance and distributed FS.
ONLY crate which supports async trait interface.
- Fuse-mt Multi-threaded Wrapper
Multi-threaded syscall dispatch, inode-to-path conversion, return-based API. Good for high concurrency & performance-sensitive FS.
- fuse-backend-rs
Supports FUSE daemons & virtio-fs, modular design, rich examples. Fits containers, virtualization, cloud storage.
Furthermore, this crate provides demo implementations of passthrough and overlayFS for FUSE development. We have built upon these to improve them and conduct large-scale tests, and have submitted bug issues to the project.
We have improved and pruned based on the fuse3 library, and clarified the forge count for the forget interface. Currently, we are making attempts such as parallel processing of requests. See rfuse3.
3. The Library We Developed: libfuse-fs
libfuse-fs is a ready-to-use filesystem library based on FUSE. This library provides implementations for various filesystem types and makes it easy to develop custom filesystems.
Features include:
- Asynchronous I/O support.
- Overlay filesystem implementation.
- Passthrough filesystem support.
- Easy-to-use API for custom filesystem development.
Reference:
https://github.com/cloud-hypervisor/fuse-backend-rs
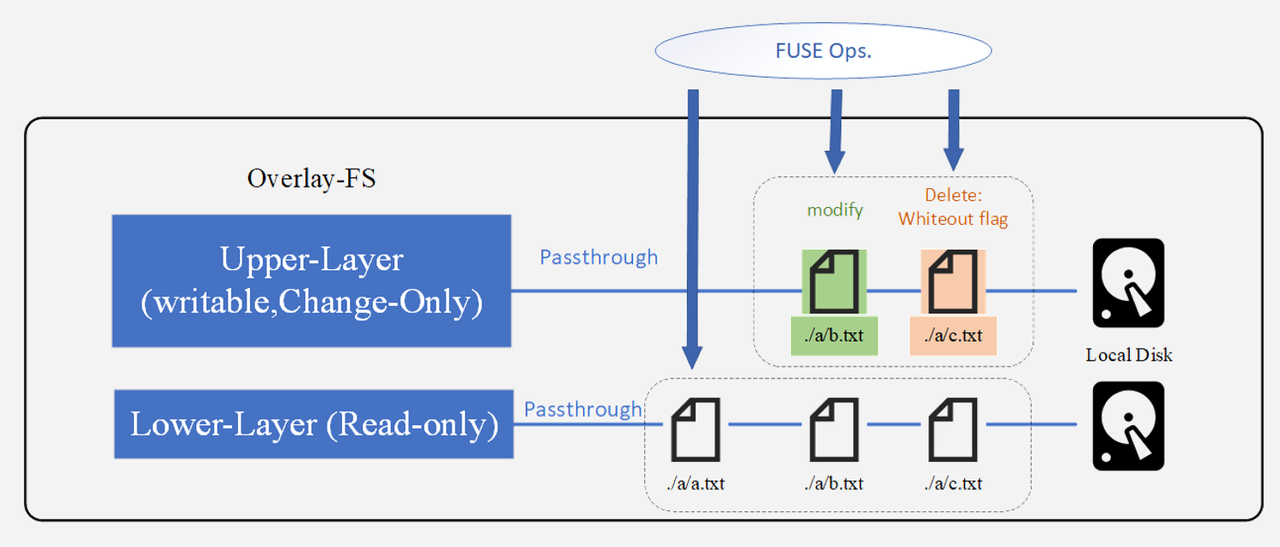
What is OverlayFS?
OverlayFS is a union file system that allows you to combine two separate layers of files into a single unified view.
- Upper-Layer (Writable, Change-Only): This is where modifications happen. Any file changes—such as edits or deletions—are stored here without altering the original data in the lower layer.
- Modify: Updated files are stored in the upper layer.
- Delete: A “whiteout” flag is created in the upper layer to hide the corresponding file from the lower layer.
- Lower-Layer (Read-Only): This layer contains the original files and remains unchanged.
- Passthrough: If a file isn’t modified, read requests are passed directly from the upper layer down to the lower layer.
- Unified View: OverlayFS can use FUSE (Filesystem in Userspace) to handle operations between layers. To the user or application, the system looks like one merged filesystem, even though the files are actually spread across two separate layers.
In essence, OverlayFS lets you efficiently manage changes without duplicating the entire dataset—ideal for scenarios like container filesystems or caching layers.
3.1 Example: Mounting an OverlayFS
- With
nix
// First, create `lowerdir`, `upperdir`, `workdir` and `mountpoint`
// Construct an `option`
let options = format!(
"lowerdir={},upperdir={},workdir={}",
lower_dirs,
Path::new(upper_dir).canonicalize().unwrap().display(),
Path::new(work_dir).canonicalize().unwrap().display()
);
// Mount OverlayFS
mount::<str, Path, str, str>(
Some("overlay"), // source: overlayfs type
Path::new(mountpoint), // target: mountpoint
Some("overlay"), // fstype: type of filesystem
MsFlags::empty(), // flags: mount flags
Some(options.as_str()), // data: overlayfs options
).unwrap();
- With libfuse-fs
// Say we have some lower directories
// Create lower layers
let mut lower_layers = Vec::new();
for lower in &lowerdir {
let layer = new_passthroughfs_layer(lower).await.unwrap();
lower_layers.push(Arc::new(layer));
}
// Create upper layer
let upper_layer = Arc::new(new_passthroughfs_layer(&upperdir).await.unwrap());
// Create overlayfs
let config = Config {
mountpoint: mountpoint.clone(),
do_import: true,
..Default::default()
};
// Here the last argument represent `root_inode`
let overlayfs = OverlayFs::new(Some(upper_layer), lower_layers, config, true).unwrap();
// Mount OverlayFS, supporting privileged and non-privileged mode
let mount_options = MountOptions::default();
Session::new(mount_options)
.mount(overlayfs, mount_path)
.await
.unwrap();
3.2 FUSE-Log
For easier debugging and observability, we developed a logging filesystem based on the FUSE trait specifically for log collection.
// LoggingFileSystem . provide log info for a filesystem trait.
pub struct LoggingFileSystem<FS: Filesystem> {
inner: FS,
fsname: String,
}
//...other interface
async fn lookup(&self, req: Request, parent: Inode, name: &OsStr) -> Result<ReplyEntry> {
let uuid = Uuid::new_v4();
let method = "lookup";
let args = vec![
("parent", parent.to_string()),
("name", name.to_string_lossy().into_owned()),
];
self.log_start(&req, &uuid, method, &args);
let result = self.inner.lookup(req, parent, name).await;
self.log_result(&uuid, method, &result);
result
}
//...other interface
This is a decorator wrapper that adds comprehensive logging to any FUSE filesystem. The LoggingFileSystem<FS> struct uses Rust generics to wrap any existing filesystem implementation and transparently logs all operations without modifying the underlying behavior.
Implementation Strategy
Each FUSE operation follows a consistent 4-step pattern:
- Generate UUID for operation tracking.
- Log method entry with parameters.
- Delegate to wrapped filesystem.
- Log results (success/error) and return original response.
The logging uses structured format: ID:{uuid}|[{method}] REQ{request} - Call: {args} for entry and ID:{uuid} [{method}] - Success/Error: {result} for completion.
Key Benefits
- Zero-overhead transparency: The wrapper preserves all original functionality, error handling, and return types while adding detailed observability. It can wrap any FUSE implementation as a drop-in replacement, making it invaluable for debugging filesystem behavior and monitoring performance without code changes to the underlying filesystem logic.
- Operation-specific enhancements: Special handling for data operations (logging byte counts), file handle tracking, and stream-based directory operations provides rich debugging context.
This design exemplifies the decorator pattern's power in Rust: using generics and trait bounds to create completely transparent, type-safe wrappers that add functionality without runtime overhead.
🌟 Our crate can be found at here
4. Challenges and How We Solved Them
Developing with FUSE often uncovers subtle interactions between the kernel, the FUSE library, and the filesystem implementation. In our case, we mounted an Ubuntu filesystem using OverlayFS of libfuse-fs and successfully executed a series of package management operations. The following section details some issues we encountered during this process, along with the approaches we used to resolve them.
Segmentation Fault When Executing apt update
Description
After mounting the Ubuntu filesystem, we performed a chroot into the environment and attempted to run apt update. However, the process consistently terminated with a fatal error, though the specific error messages varied between executions. In some cases, the output reported:
chroot . /bin/bash: terminated by signal SIGSEGV (Address boundary error)
In other cases, it reported:
chroot . /bin/bash: terminated by signal SIGILL (Illegal instruction)
Analysis
At first, we tried to locate the code segment where the error occurred. We inspected the libfuse-fs logs, but found no obvious errors. Then, we added the --verbose flag to apt and used strace to trace system calls. To our disappointment, the program crashed with the same error and provided no additional information in verbose mode. The system logs were even stranger — it always crashed immediately after an rseq call, which was irrelevant to our filesystem.
We found it difficult to establish a clear connection between the error and the underlying issue — it could have been a logic error in our implementation of a certain call, or an interaction between apt and the filesystem. One major challenge was that apt update acted like a black box; we had no insight into its internal behavior. Moreover, the logs were massive, making it difficult to pinpoint the specific system call that triggered the error.
Next, we searched for alternative ways to reproduce the error, and eventually found some. One method was to execute the command cat a.txt 100 times in a loop:
for i in {1..100}; do cat a.txt; done
This suggested that the error might be related to concurrency. A strong indication came from Valgrind — suspecting stack overflow or buffer overflow issues, we used Valgrind to detect such problems. Surprisingly, when we ran libfuse under Valgrind, the error disappeared and everything ran normally! We encountered a Heisenbug. This is typically caused by Valgrind significantly slowing down program execution, which alters the timing and sequence of events, thereby masking race conditions.
To verify this, we employed ThreadSanitizer to detect data races. It confirmed a race condition between read and write operations. The root cause was a missing lock. For example, the original code in the write() function was:
let data = self.get_data(fh, inode, libc::O_RDONLY).await?;
let f = unsafe { File::from_raw_fd(data.borrow_fd().as_raw_fd()) };
// ...
let res = f.write(data)?;
In this code, concurrent reads and writes could occur without protection. To fix this, we introduced a lock to protect the shared data:
let data = self.get_data(fh, inode, libc::O_RDONLY).await?;
let _guard = data.lock.lock().await;
let f = unsafe { File::from_raw_fd(data.borrow_fd().as_raw_fd()) };
// ...
let res = f.write(data)?;
The fix itself was straightforward, but this experience reaffirmed that real-world concurrency bugs are notoriously difficult to debug.
No Such File or Directory?
Description
When executing apt update, we encountered the following errors:
E: Unable to determine file size for fd 9 - fstat (2: No such file or directory)
E: Problem closing the file - close (2: No such file or directory)
E: The repository 'http://archive.ubuntu,com/ubuntu noble InRelease’ provides only weak security information.
Analysis
This time, we dived into the libfuse-fs logs and observed an interesting phenomenon. The second write operation succeeded, but immediately afterward, the filesystem could not locate the file, as shown below:
[write] REQ Request { unique: 48128, uid: 0, gid: 0, pid: 22435 }- - Call: inode=1187, fh=843, offset=122880, data_len=2362, write_flags=0, flags=32770
[libfuse_fs::overlayfs::OverlayFs] write - Wrote 2362 bytes
[write] - Success: ReplyWrite { written: 2362 }
[getattr] REQ Request { unique: 48134, uid: 0, gid: 0, pid: 22435 }- - Call: inode=1187, fh=, flags=0
[TRACE libfuse_fs::overlayfs] lookup_node: parent inode 1187 not found
[getattr] - Error: Errno(2)
[flush] REQ Request { unique: 48136, uid: 0, gid: 0, pid: 22435 }- - Call: inode=1187, fh=843, lock_owner=12972504841675058382
[TRACE libfuse_fs::overlayfs] lookup_node: parent inode 1187 not found
[flush] - Error: Errno(2)
When apt tries to close a file, it calls flush. Since flush returned Errno(2), apt concluded that the file did not exist and reported the error. But why?
Tracing the logs backward, focusing on inode 1187, we found that an unlink operation was called immediately after the inode was created:
[create] REQ Request { unique: 47990, uid: 0, gid: 0, pid: 22435 }- - Call: parent=10, name=clearsigned.message.zI9jBN, mode=33152, flags=32962
[create] - Success: ReplyCreated { ttl: 5s, attr: FileAttr { ino: 1187, size: 0, blocks: 0, atime: Timestamp { sec: 1752738743, nsec: 198890733 }, mtime: Timestamp { sec: 1752738743, nsec: 198890733 }, ctime: Timestamp { sec: 1752738743, nsec: 198890733 }, kind: RegularFile, perm: 384, nlink: 1, uid: 0, gid: 0, rdev: 0, blksize: 4096 }, generation: 0, fh: 843, flags: 164034 }
[unlink] REQ Request { unique: 47992, uid: 0, gid: 0, pid: 22435 }- - Call: parent=10, name=clearsigned.message.zI9jBN
[unlink] - Success: ()
When unlink is called, we attempt to delete the file, but deletion does not actually occur until no process holds an open file descriptor to it. In our implementation, we use a deleted hashmap to store inodes that have been unlinked but still have a non-zero lookup count. This explains why the unlink succeeded and why successful write calls could be observed.
The real issue lies in the lookup_node() method, which is invoked by both getattr and flush to retrieve inode information. The original lookup_node() calls get_active_inode() to find the inode, but this method only searches the active inode hashmap and completely ignores the deleted map. If get_active_inode() returns None, we assume the file does not exist, leading to the error. The correct approach is to consider the deleted map as well.
In fact, there is a known pattern called "create-and-unlink". To create an anonymous temporary file, a process creates the file, obtains its file handle or descriptor for reading or writing, then immediately deletes it. When the process holding the file handle exits, the OS automatically reclaims the file. Because the file exists only in the deleted state, other processes cannot access or modify it, avoiding naming conflicts and race conditions. Using the C standard library function tmpfile(), we can reproduce the "create-unlink-write-flush" call chain.
A robust filesystem should handle such cases correctly.
Something About link
Description
After fixing several earlier bugs, we were able to execute apt update successfully. However, when we proceeded with apt install, a new set of errors emerged—most of them occurring around the link system call.
Analysis
Before diving into the issue, let's briefly review how a hard link is supposed to work. When creating a hard link, if the target file does not exist in the upper layer, it should first be copied from the lower layer to the upper layer. Then, a new directory entry is created to represent the linked file. So far, so good—at least in theory. The relevant code looked like this:
let src_node = self.copy_node_up(ctx, Arc::clone(src_node)).await?;
let src_ino = src_node.first_layer_inode().await.2;
match self
.lookup_node_ignore_enoent(ctx, new_parent.inode, name)
.await?
{
Some(n) => {...}
None => {
// Copy parent node up if necessary.
let new_node: Arc<Mutex<Option<OverlayInode>>> = Arc::new(Mutex::new(None));
new_parent
.handle_upper_inode_locked(
&mut |parent_real_inode: Option<Arc<RealInode>>| async {
let parent_real_inode = match parent_real_inode {
Some(inode) => inode,
None => {
error!("BUG: parent doesn't have upper inode after copied up");
return Err(Error::from_raw_os_error(libc::EINVAL));
}
};
// Allocate inode number.
let path = format!("{}/{}", new_parent.path.read().await, name);
let ino = self.alloc_inode(&path).await?;
let child_ri = parent_real_inode.link(ctx, src_ino, name).await?;
let ovi =
OverlayInode::new_from_real_inode(name, ino, path, child_ri).await;
new_node.lock().await.replace(ovi);
Ok(false)
},
)
.await?;
// new_node is always 'Some'
let arc_node = Arc::new(new_node.lock().await.take().unwrap());
self.insert_inode(arc_node.inode, arc_node.clone()).await;
new_parent.insert_child(name, arc_node).await;
}
}
In our implementation, after copying src_node from the lower layer, we allocated a new inode for the newly linked file and inserted this node into its parent directory. This may sound reasonable, but it is fundamentally incorrect. A hard link is supposed to reuse the same inode as the source file, not to allocate a completely new one. Treating it as a separate file breaks fundamental filesystem semantics, leading to unpredictable errors.
The correct approach is to create only a new directory entry and have it reuse the existing inode of the source file:
None => {
// Copy parent node up if necessary.
// trace!("do_link: no existing node found, creating new link");
new_parent
.handle_upper_inode_locked(
&mut |parent_real_inode: Option<Arc<RealInode>>| async {
let parent_real_inode = match parent_real_inode {
Some(inode) => inode,
None => {
error!("BUG: parent doesn't have upper inode after copied up");
return Err(Error::from_raw_os_error(libc::EINVAL));
}
};
parent_real_inode.link(ctx, src_ino, name).await?;
Ok(false)
},
)
.await?;
// Points to the same node as src_node.
new_parent.insert_child(name, Arc::clone(&src_node)).await;
}
We also discovered that libfuse-fs itself does not handle hard links properly and exhibits several related issues, though we will not expand on those here.
Summary
Diagnosing application-level errors that originate from underlying filesystem issues can be tricky—especially when working with complex codebases. To make troubleshooting easier, it’s best to narrow the debug scope and use the minimal set of operations needed to reproduce the problem. Equally important is having a well-structured logging system that surfaces actionable, relevant details.
If you’re exploring FUSE filesystems or looking for a lightweight, practical starting point, we invite you to try libfuse-fs. Whether you want to integrate it into your own project, experiment with new ideas, or help improve its capabilities, your contributions are welcome and valued.
Authors
- Ruiji Yu, Nanjing University
- Xiaoyang Han, University of Science and Technology Beijing